– 논문 제목: Momentum Contrast for Unsupervised Visual Representation Learning
– 종이 링크: https://arxiv.org/pdf/1911.05722.pdf (CVPR 2020)
논문 요약
메모리 뱅크와 같은 새로운 사전 기반 대조 학습 구조가 제안되었으나, 메모리 뱅크와의 차이점은 배치 데이터가 바뀔 때마다 키 인코더에서 추출한 임베딩을 고정된 크기의 사전에 추가한다는 점이다. 모든 데이터를 사전에 임베딩합니다. 제거하거나 지속적인 갱신이때 사전의 크기에 따라 일괄 임베딩을 얼마나 많이 포함할지 결정됩니다. 그리고 키 인코더는 기존 키 인코더와 현재 쿼리 인코더 간의 가중 평균입니다. 모멘텀 업데이트 그러나 기존의 키 인코더에 훨씬 더 큰 가중치를 부여함으로써 질의 인코더와 키 인코더의 임베딩 간극이 벌어지지 않는다.
논문에 대해 이야기하다
시작하기 전에
1. 비지도 학습은 NLP에서 자주 사용되는 학습 방법입니다. 비지도 학습은 데이터의 특성으로 인해 단어와 하위 단어에 대한 신호 표현을 사전에 이산적으로 저장하고 검색할 수 있기 때문에 자주 사용됩니다. 반면에 비감독 표현 학습은 데이터의 연속적인 특성 때문에 CV에서 잘 사용되지 않았습니다.
2. 이를 보완하기 위해 “동적 사전”이라는 실제 사전이 아닌 인코더에서 필요할 때마다 표현을 추출하여 사용하는 방법이 등장했습니다.
삼. 본 논문에서는 새로운 형태의 동적 사전을 제안한다. 보다 정확하게는 새로운 유형의 동적 사전을 기반으로 하는 대조적인 자기 지도 학습 프레임워크입니다. (부거) 제안
4. 필요할 때마다 꺼내서 사용하는 것이 아니라 큐 구조를 가지고 있기 때문에 배치마다 키 표현을 업데이트하면서 딕셔너리로 사용한다. 그리고 그 목적은 부정적인 샘플의 표현을 임시로 저장하는 것입니다.
5. 논문에서 사전의 두 가지 중요한 조건으로 크기가 충분히 큰가? (크기가 큰)키 표현 업데이트가 얼마나 강력하고 일관되게 진행되는지 (일관된) 즉, 새로 제안된 대기열 구조의 동적 사전은 모든 조건을 만족합니다. (조건 충족 방법은 바로 뒤에 나옵니다.)
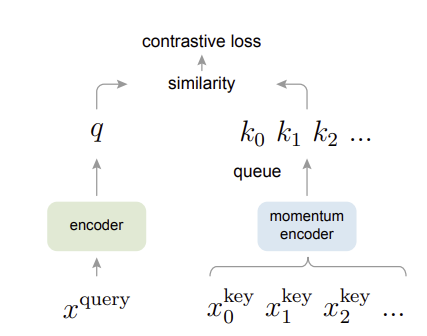
운동량 대비(MoCo)
1. 여기서 동적 사전은 먼저 키 인코더에서 특정 크기의 배치(즉, 미니 배치)에 대한 키 표현을 추출하고 대기열 구조로 각 배치에 일정량의 K 표현을 추가하고 동시에 업데이트하면서 크기가 초과되면 제거합니다.
2. 이때 대기열 크기를 크게 설정하십시오. (그래서 유사성 비교를 위해 여러 유형의 음성 샘플이 사용됩니다.) 사전의 두 가지 중요한 조건 중 하나인 큰 사이즈 만족하다
삼. 사전 사용의 가장 큰 문제점은 그 크기가 너무 크고 업데이트 비용이 너무 높다는 것입니다. 위의 문제를 해결하기 위해 종이는 키 인코더에 대한 백 프롭을 차단합니다. 처음에는 키 인코더 쿼리 인코더와 동일 초기화 후 학습 과정에서 가장 최근에 업데이트된 쿼리 인코더와 기존 키 인코더 간에 가중 평균을 구하여 키 인코더를 업데이트합니다.
4. 기존 상태를 고려하여 다음 단계로 업데이트되는 점으로 인해 모멘텀 업데이트 기존 상태에 훨씬 더 가중치를 부여함으로써 사전의 나머지 중요한 조건은 일관된 업데이트 만족하다 (실험 결과 이와 같은 업데이트가 서로 다른 인코더 임베딩 사이의 간격을 좁히는 것으로 나타났습니다.)
5. 다음은 전체 MoCo의 작동 방식입니다. 알고리즘 1 에서 찾을 수 있습니다

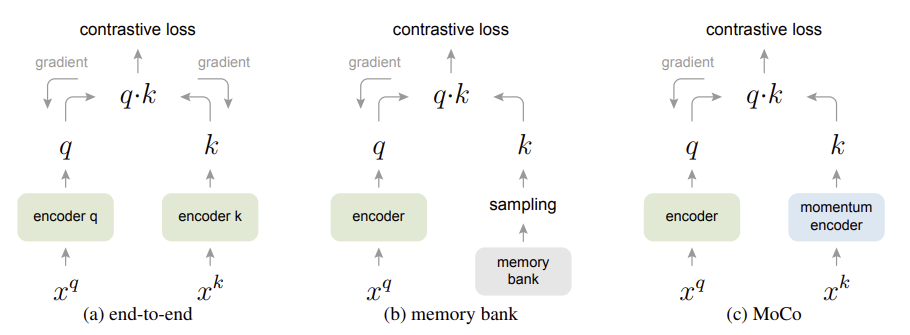
6. 위의 그림 2는 MoCo를 다른 대조 학습 아키텍처와 비교합니다. 자세한 비교 정보는 (여기)장의. 3에서 확인하실 수 있습니다.
모코 추가 정보
1. MoCo에서 사용하는 대조 손실 함수는 다음과 같습니다. 정보 모두.
2. 프리텍스트 태스크는 인스턴스 식별 작업 표현 학습에서 동일한 이미지에서 증강된 이미지는 서로 멀리 떨어져 있고 다른 이미지에서 증강된 모든 이미지는 서로 가깝습니다.
삼. 일반적으로 쿼리 인코더와 키 인코더에서 추출한 특징 표현 각각에 대해 배치 정규화(BN)를 수행한다. 그러나 이 논문은 키 측의 입력 셔플링과 다른 하위 집합의 BN에만 관심이 있습니다. (셔플링 BN) 일반적인 방식으로 BN을 수행했을 때 표현 학습 효과가 감소한 것을 확인한 결과 각 질의 BN 간에 교환되는 샘플 정보가 중복되어 정보 유출이 발생하여 너무 쉽게 저손실 솔루션을 찾는 지름길 학습 현상이 발생함 키 BN. 짐작했다.
4. BN을 섞는 구체적인 방법은 다음과 같다. 주어진 배치가 섞이고 다른 GPU에 배포되며 각 GPU의 키 인코더에서 기능 표현이 추출됩니다. 그런 다음 BN은 각 GPU에서 독립적으로 수행되고 마지막으로 순서가 복원됩니다. 이 방법은 각 질의 BN과 키 BN 내에서 교환되는 샘플 정보의 중복을 방지합니다.
실험
1. 선형 분류
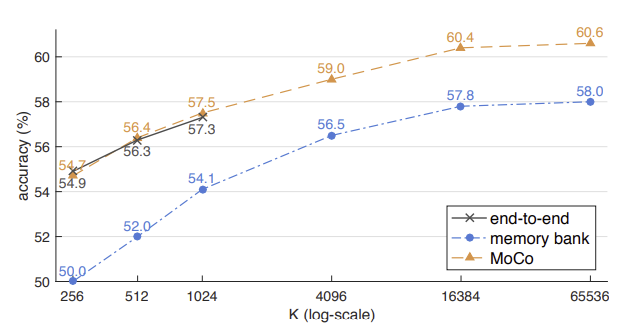
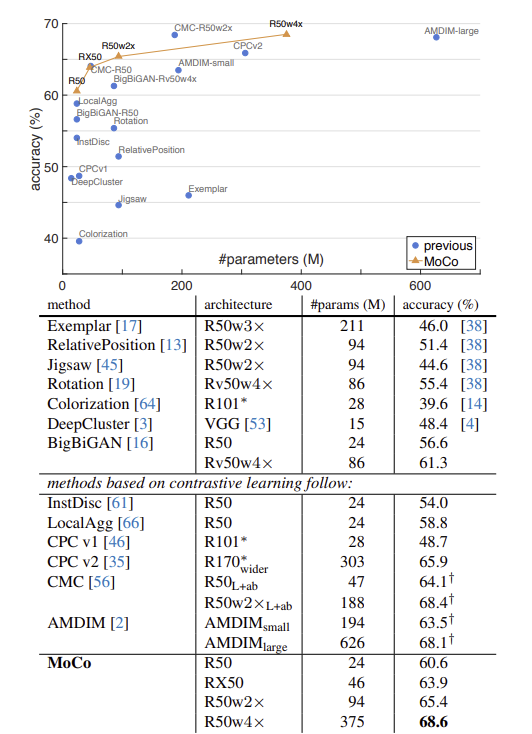
2. 전송 기능
1) PASCAL VOC-객체 감지
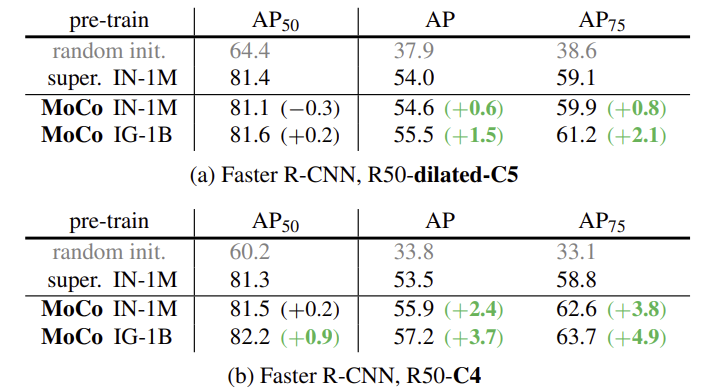
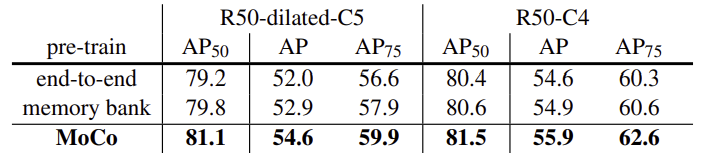
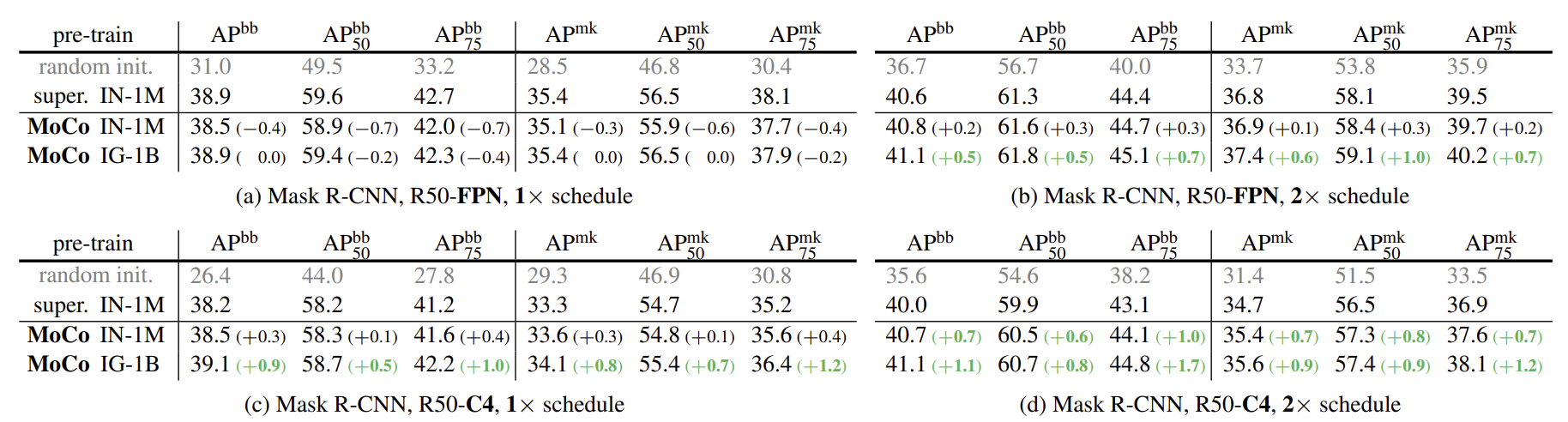
2) COCO-객체 감지 및 세분화
최종 업데이트: 2023. 04. 16.
임태준 작사